


We introduce Being-H0, the first dexterous Vision-Language-Action model pretrained from large-scale human videos via explicit hand motion modeling.
Key Concept
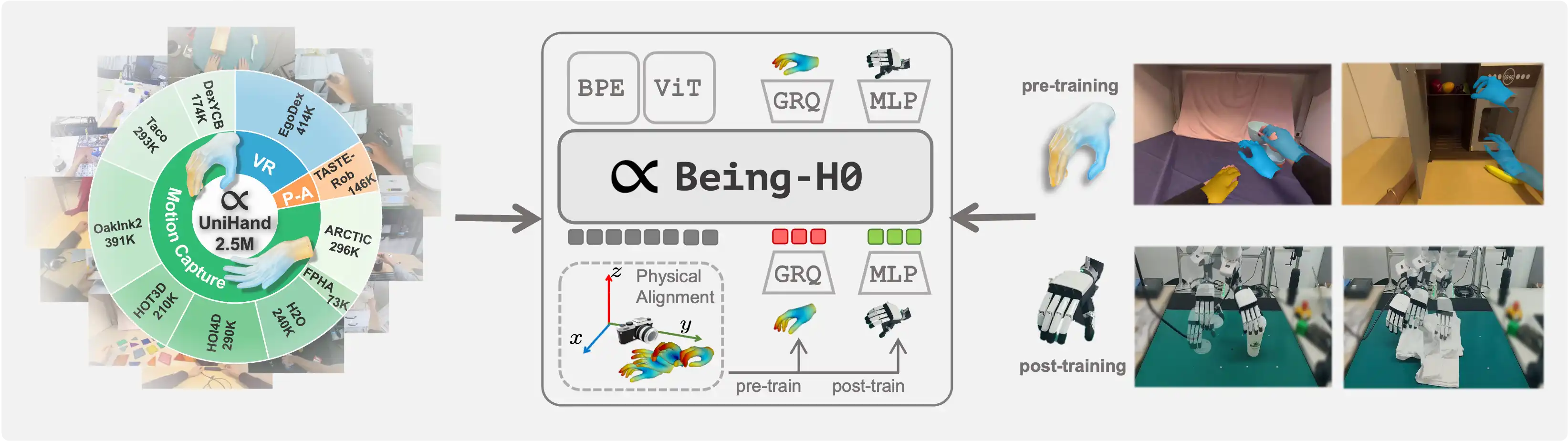
Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the UniHand dataset via physical instruction tuning. By explicitly modeling hand motions, the resulting foundation model seamlessly transfers from human hand demonstrations to robotic manipulation.
Interactive Demo
Robot Demo (1x)
Unfold Clothes
Showcasing multi-finger coordination to manipulate a deformable object.
Close Lid
Showcasing high precision and stable control by securely closing a cup lid.
Close Toolbox
Demonstrating interaction with articulated objects by smoothly closing a hinged toolbox.
Pick and Place
Executing natural language commands to test language-grounded manipulation.
Pick and Place (clutter)
Locating and grasping a target in a cluttered scene, highlighting robust perception.
Pour Cup
Highlighting smooth and precise control by pouring items from one container to another.
Overview
The text tokenizer and visual encoder are shared by both pretraining and post-training. For pretraining and hand motion/translation tasks, Being-H0 generates outputs in an autoregressive manner. For post-training and downstream manipulation tasks, Being-H0 incorporates a set of learnable queries as the action chunk for prediction.
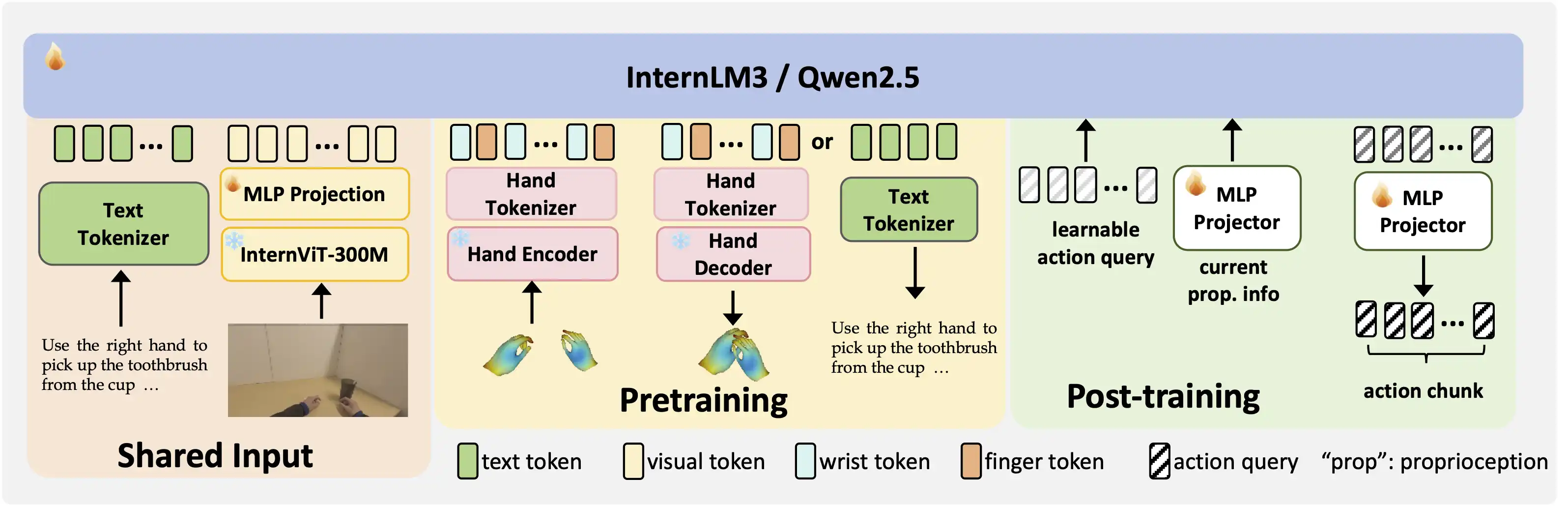
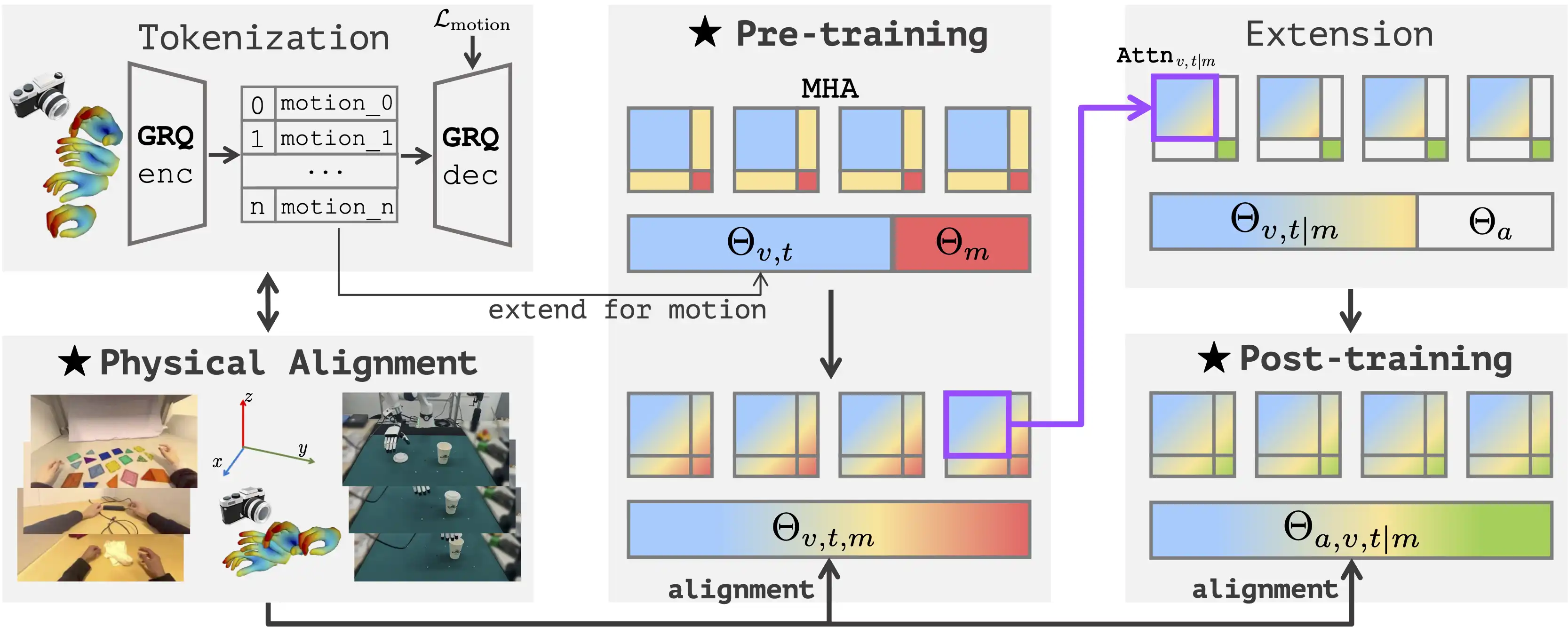
Physical Instruction Tuning
Physical Instruction Tuning unifies human video datasets and robotic manipulation data. We extend VLM to include motion and action tokens, using multi-head attention across vision, text, motion, and action modalities to create a unified VLA model for robotic tasks.
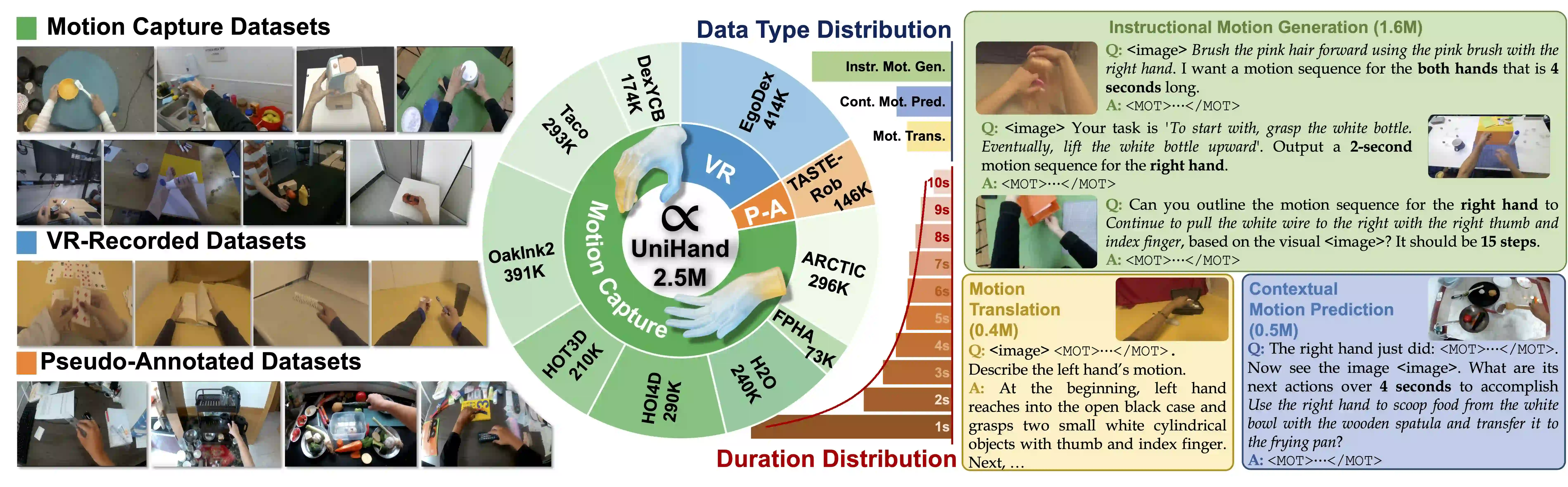
UniHand-2.5M
The overview of our UniHand-2.5M. Left: The scenes and tasks from different data source types. Mid: The distribution of different data sources, data types, and durations. Right: Samples from different data types.
Experiments
Scaling Performance
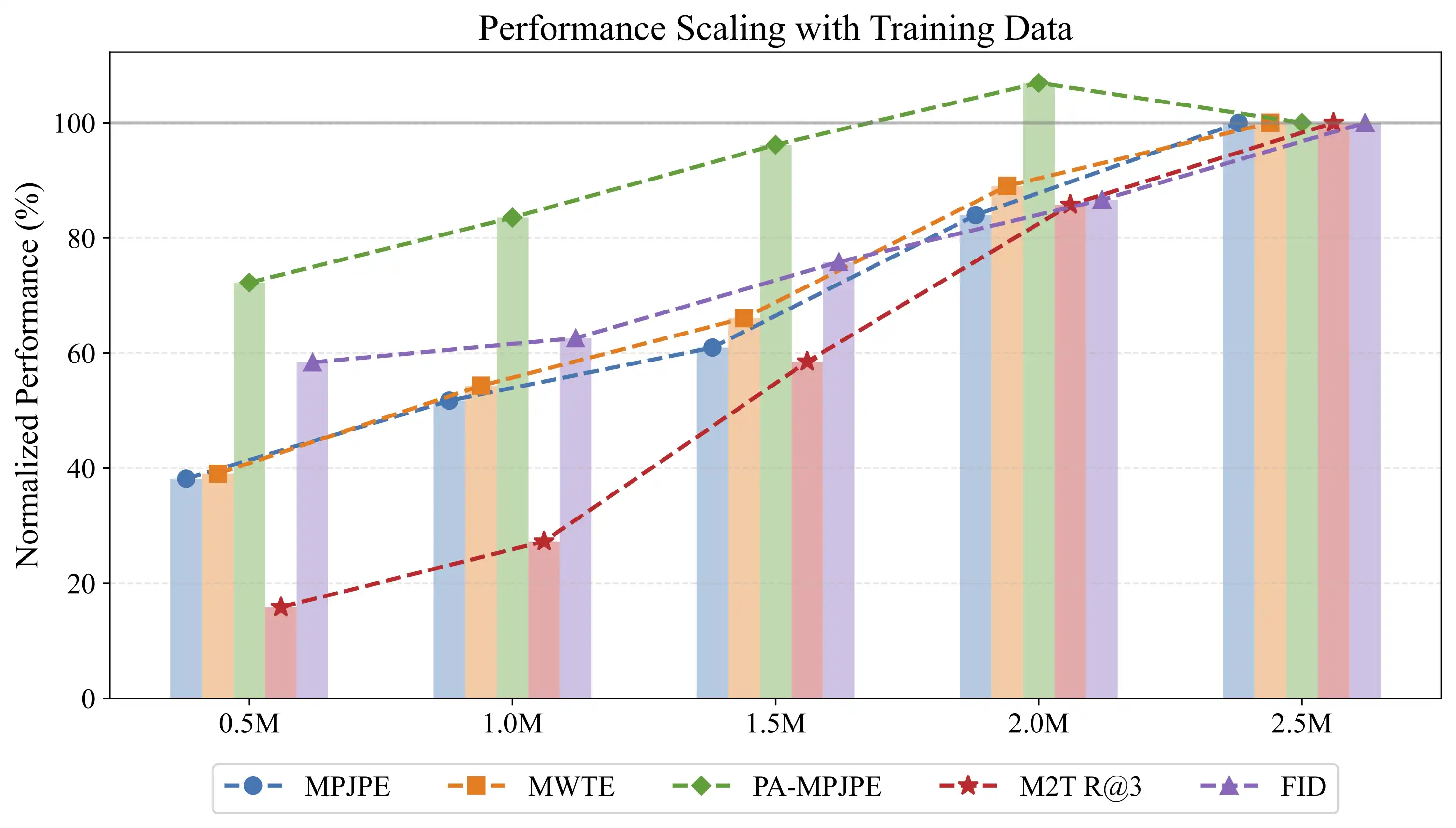
The performance of Being-H0 alongside the increasing training data scale for visual-grounded hand motion generation. It scales well with model and data sizes.
Robot Experiments
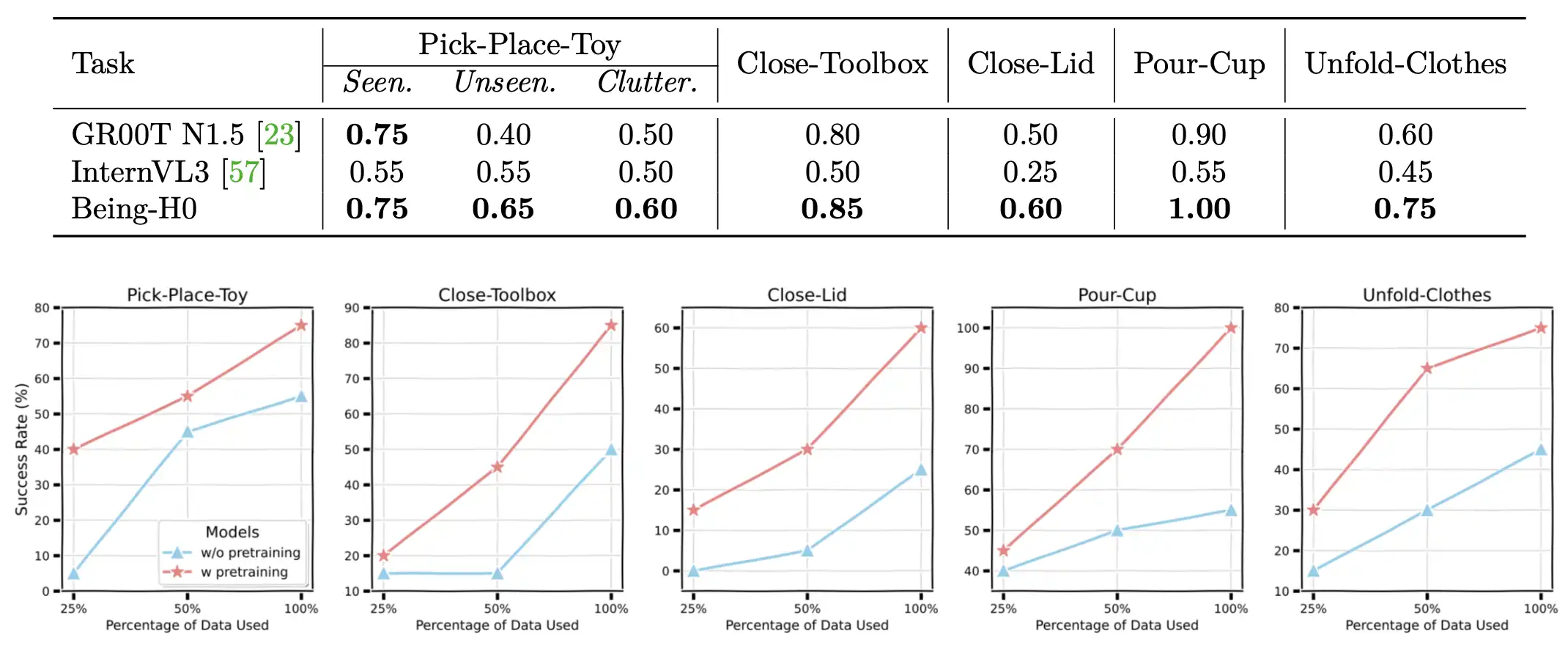
The advantages of Being-H0 are particularly remarkable in dexterous manipulation tasks, where it substantially improves the success rate and requires much less teleoperated demonstrations.
Citation
@article{beingbeyond2025beingh0,
title={Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos},
author={Luo, Hao and Feng, Yicheng and Zhang, Wanpeng and Zheng, Sipeng and Wang, Ye and Yuan, Haoqi and Liu, Jiazheng and Xu, Chaoyi and Jin, Qin and Lu, Zongqing},
journal={arXiv preprint arXiv:2507.15597},
year={2025}
}